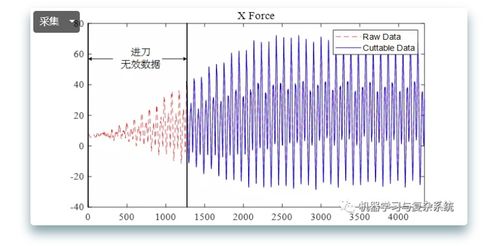
在数据分析和机器学习项目中,异常数据处理是数据处理流程中至关重要的一环。异常数据,也称为离群值(Outliers),是指与大多数数据点显著不同的观测值。这些数据可能由测量错误、录入错误、系统故障或真实的极端事件引起。如果未得到适当处理,异常数据可能导致模型性能下降、分析结果偏差,甚至误导决策。
异常数据的识别方法多种多样,包括基于统计的方法(如Z-score、IQR方法)、基于距离的方法(如K-近邻算法)以及基于聚类的方法(如DBSCAN)。选择合适的方法取决于数据的分布特征、业务场景以及异常数据的性质。
处理异常数据的常见策略包括删除、替换、修正或保留。删除异常值适用于数据量充足且异常值明显由错误导致的情况;替换则常用均值、中位数或预测值填充;修正适用于已知错误来源的数据;而在某些场景下,如欺诈检测,异常数据本身具有重要价值,应予以保留并单独分析。
在实际应用中,异常数据处理需要结合领域知识。例如,在金融交易数据中,极端高额的交易可能既是异常也是关键风险信号;在医疗数据中,异常生理指标可能指向特殊病例。因此,自动化处理与人工审核相结合往往能取得更好效果。
系统化的异常数据处理不仅能提升数据质量,还能增强模型的鲁棒性和分析结果的可靠性,为后续的数据挖掘和决策支持奠定坚实基础。